Project: RAG System
PDF Querying System
Lawyers have tons of PDFs... but how do they find precise answers fast? Do they have to search through an entire book or hundreds of pages of PDFs? Not anymore — just upload and get the answer relevant to your query.
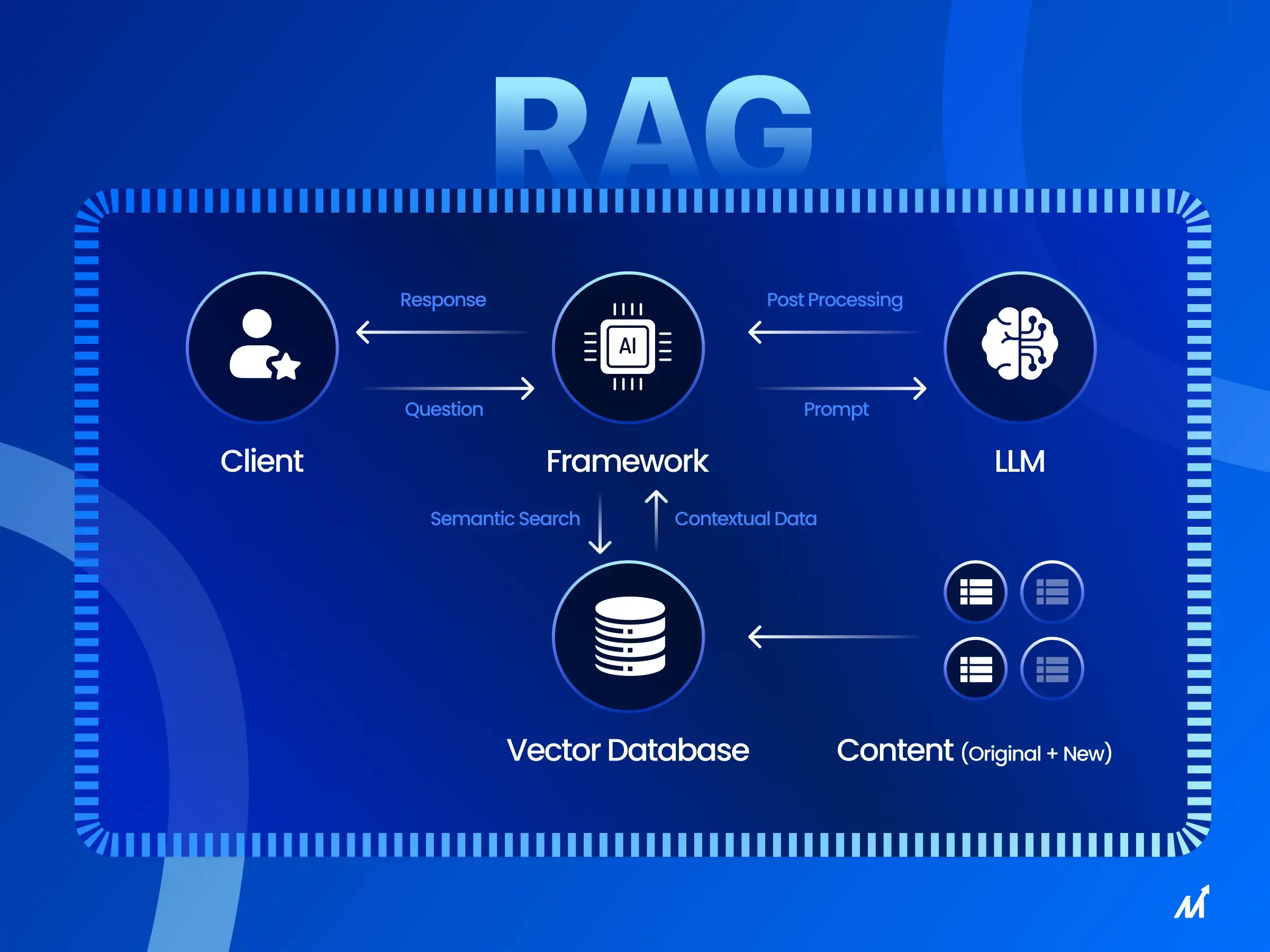
That's the problem my RAG AI app solves. Upload large PDFs which are automatically parsed & chunked using PyPDFLoader + RecursiveCharacterTextSplitter (LangChain). Embeddings are generated with OpenAI text-embedding-3-small (1536-dim) and stored in Pinecone (serverless) for real-time vector search.
Query answers are returned via ChatOpenAI + RetrievalQA, ensuring accurate, context-aware responses — not just generic LLM text. Deployed on AWS Elastic Beanstalk with GitHub CI/CD, making it scalable and production-ready.
Key Features
- User-friendly interface to upload any PDF document
- Advanced semantic search to find the most relevant text chunks
- Generative AI model provides conversational, accurate answers based on retrieved context
- Secure and scalable vector database for managing document embeddings
- Production-ready deployment with CI/CD pipeline